
[AI X Music] Music transformer 모델의 분석과 코드 적용 (설명 제일 잘되어 있음)
카테고리: medium
Music transformer 설명: Universial하게 이용가능한 AI model
Music transformer 설명: Universial하게 이용가능한 AI model
Music transformer의 코드분석과 실 적용

Music transformer란?
음악창작을 도와줄 수 있도록 설계된 (성능이 좋은)인공지능 모델 중 하나로
Transformer라는 유명한 인코더-디코더 형태의 모델을 음악창작에 맞게 살짝 변형한 모델
읽기 전 사전지식: transformer, attention, encoder, decoder, 간단한 행렬 계산 지식
Transformer vs Music transformer
(트랜스포머의 구조에 대해 이미 알고 있다고 가정한다)
트랜스포머는 self-attention을,
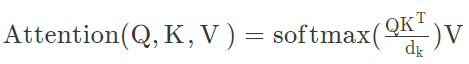
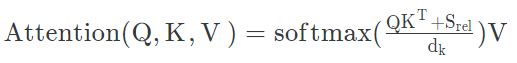
뮤직 트랜스포머는 relative attention을 넣어.
아울러 relative attention을 넣어주면, 상대위치정보가 들어가있으므로 트랜스포머의 인코더, 디코더 전에 넣어주던 positional encoding이 필요 없습니다.
왜 relative attention을 넣어주냐 생각을 해보면, 음악속에 있는 반복적인 구조(전주-후렴-2절-후렴)와, 마디별로 반복되는 악기의 음악적 요소(아르페지오)들을 잡아낼 수 있기 때문이다. 지금 읽고 있는 이 글에서는 반복되는 단어는 있을망정 반복되는 문장구조는 존재하지 않는다. 하지만 음악에서는 반복되는 마디와, 반복되는 멜로디는 어디서나 쉽게찾아볼 수 있기 때문에 음악 데이터(노트)간의 상대적인 정보에 초점을 맞추는 Music transformer가 음악에 있어서 더욱 적합하다고 볼 수 있다.
떴다 떴다 비행기를 떠올려보자..
실제로 구현할 때, 코드상으로 어떤 차이가 있는지 글의 맨 마지막 섹션에 적어두도록 하겠습니다. 실제로 Music Transformer를 구현까지 해보고 싶으시다면 마지막까지 읽어주시기 바랍니다(하핫)
어텐션
뮤직 트랜스포머 논문에서는 relative attention을 적용하는 방법에 대해 초점을 맞추어 설명을 해준다. relative attention(상대어텐션)을 사용할 때에는 메모리사용량이 L²이 드니까, skewing이라는 방법으로 L²이 아닌 L의 메모리사용량으로 계산하는 방법을 제안하고 있다.
그러니까, 바로 적용해보고 싶다면 Music transformer논문을 읽어보면 되고, Music transformer에 들어가는 상대에텐션의 계산에 대해 궁금하신 분들은 shaw아저씨의 relative attention에 관한 논문을 읽어보시면 될 것 같습니다. 논문들은 글 마지막에 링크 걸도록 하겠습니다.

.
중간정리
Transformer를 변형한게 Music Transformer이다. 뭐가 달라졌냐면 relative attention을 사용한다는 점이다. 왜? 음악은 상대적인 위치정보가 중요하니까
.
.
Relative attention
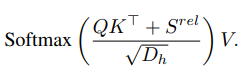
S(rel)저게 상대정보값을 가지고 있는데,(이하 S)
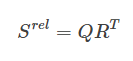
Q = 쿼리벡터, R = relative position 정보값을 가지고 있는 벡터

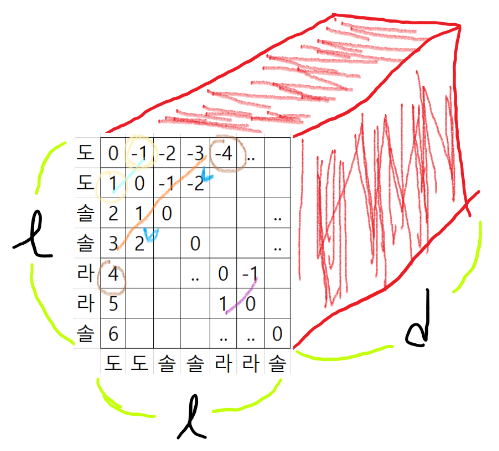
E는 임베딩벡터이다. 이걸 통해서 R을 만드는데, R은 상대적으로 얼마나 떨어져있는지를 나타내는 3차원 벡터이다. 그러니까 C4와 D4와 같은 노트들이 얼마나 유사한지를 나타내는게 아니라, 실제 악보상에서 어떤 시간적 거리를 가지고 있는지를 나타낸다. 예를들어 ‘반짝반짝 작은별’ 노래가(도도 솔솔 라라 솔~) 있다고 하면
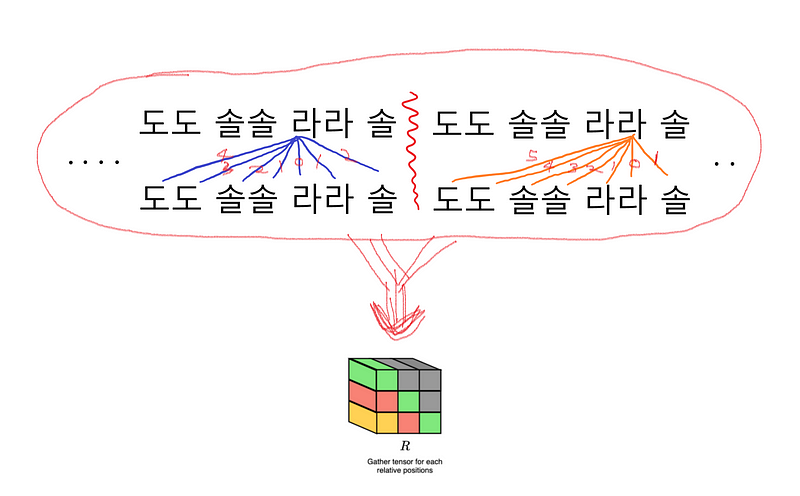
각 음들이 옆의 음들과 어떤 거리가 있는지를 나타낸다. 이렇게 나타내면 간단해 보이지만, 실제로는 음들의 길이도 다 다르고, 화음도 있으며, 똑같은 음도 옥타브에 따라 다르고, 훨씬 많은 벡터들이 다양한 거리를 가지고 있다. vocab의 수가 NLP쪽보다는 적을 것 같긴 하지만, 한편으로는 멜로디가 조금만 복잡해져도 L이 엄청나게 늘어나므로 relative attention을 계산해야 할 양이 엄청나게 늘어난다.
개인적으로는 노트의 (연주길이경우의 수)*(코드의 종류) 만큼의 vocab을 가지도록 임베딩을 하는방법으로 알고있는데, 좀더 효율적인 방법이 있다면 댓글로 알려주시면 감사드리겠습니다 ;)
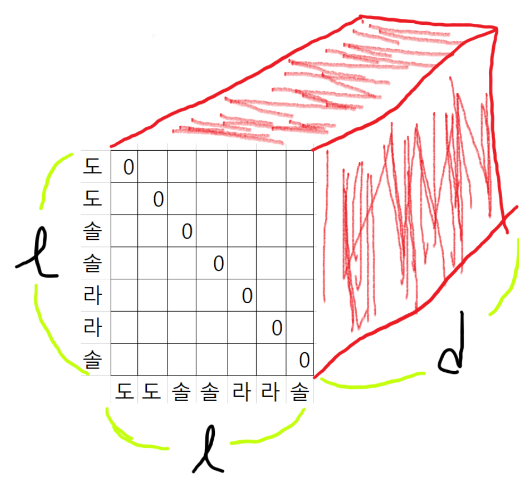
그래서 R벡터는 (L, L, d)의 크기를 가지게 되고
Q는 (L, d)의 2차원이므로 실 연산시에는, Q를 (L, 1, d)로 reshape해주어서 R과 곱해주면 된다.
그러면 S의 크기는 (L, 1, d) * (L, d, l) => (L, 1, L) => reshape => (L, L)
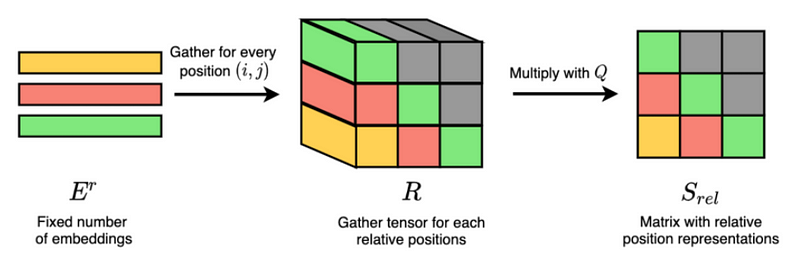
저렇게 데이터간의 상대적 거리(S)에 해당하는 벡터를 구해서 self attention과 함께 계산해주면 relative attention을 구할 수 있다.
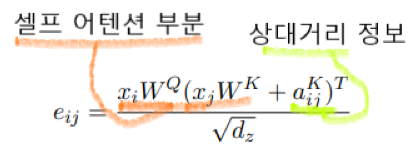
그런데 이걸 계산할 때, L²d의 복잡도가 생기므로 skewing이라는 기법을 통해 시간복잡도를 Ld로 낮출 수 있다(라는 내용까지 논문에 있습니다)
.
Skewing

생각해보면 똑같은 계산을 두 번 하는 모습을 볼 수 있다. 이는 skew matrix가 됨을 쉽게 짐작할 수 있다. 그리고 이 상대위치 정보들은 절대위치 정보들로부터 얻어올 수 있다.
전체적인 프로세스는 아래와 같다. 일단 절대위치벡터로 만든 다음, reshape해줘서 결국 S벡터를 얻어내는 방식인데, 본 글의 목적은 relative attention을 이해하고 코드에 적용하는 방법이므로 간단하게 넘어가겠다.

처음 Q를 곱하고, 절대정보가 있는 상태에서 , 마스킹하고, reshaping해줌으로써 얻어낸다. 이 방식은 relative attention논문 이후 Music transformer논문에서 처음 나온 것 같은데, 이 (어거지)방식으로 복잡도를 줄여준 것 만으로도 이미 의미있는 연구이지 않나 싶다.
아래에서 skewing을 코드에 적용하며 좀 더 알아보도록 하겠습니다.
.
중간정리
Transformer를 변형한게 Music Transformer이다. 뭐가 달라졌냐면 relative attention을 사용한다는 점이다. relative attention은 상대정보 벡터 R을 포함하고 있는데, 그거 구할 때 계산 많이해야하니까 skewing이라는 트릭으로 계산량을 줄여줄 수 있다.
.
코드적용
Music Transformer를 검색하면 저 jason9693이라는 분이 가장 먼저 나온다. 코드가 좋으니 저걸 그대로 사용해도 되지만

이분의 코드에 positional embedding이 들어가 있다. 그러나
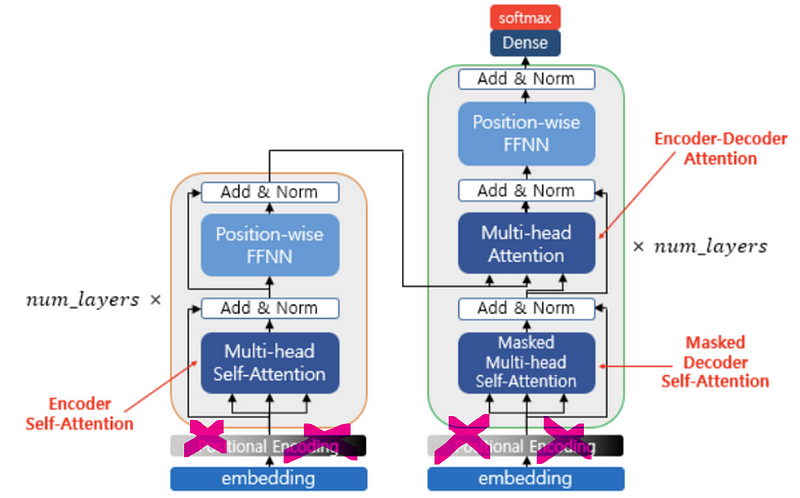
트랜스포머와 다르게 relative attention을 사용하면 positional encoding을 따로 해줄 필요가 없기에 저 부분 수정해서 사용하면 될 것 같다. (혹시.. relative attention이 있는 상태에서 positional encoding을 또 해주면 성능이 좋아지나? 했지만 해당 근거는 찾을 수 없었다, 아마 실수로 넣으신게 아닐까 싶다)
그렇다면 relative attention을 코드로 어떻게 구현하는지 살펴보도록 하겠습니다
.
Relative attention(skewing방식) 코드 구현
아래와 같이 차근차근 4가지 단계를 통해 S를 만들어주면 된다
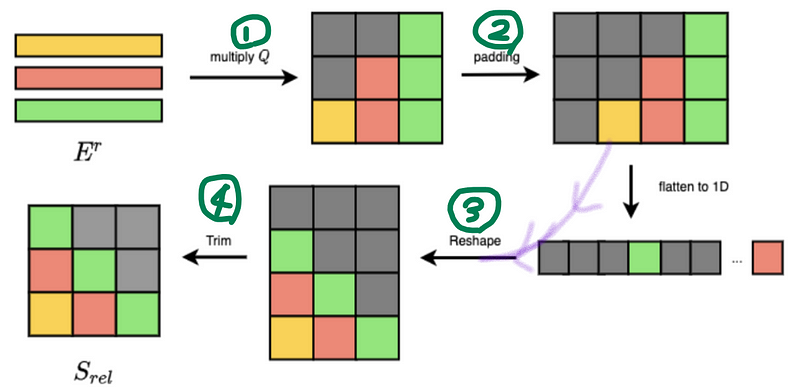
S(rel)은 왜 S일까 생각해 보았는데… shaw아저씨가 쓴 논문의 relative attention이라 S(rel)이 아닌가?? 라고 조심스레 추측해 본다
1번을 보면, Q쿼리벡터와 E임베딩 벡터를 곱해준다.

2번처럼 이제 left에 마스킹을 해주면 된다

3번, reshape를 해주고

4번 뚜껑을 떼어내주면 S가 완성~

그후 S를 이용해서 어텐션을 계산해주면 된다


— — — — — — — — — —
1234과정중 필자는 pad후 reshape하는 과정이 헷갈렸었는데, 한번 어떻게 변환되는지 연습장에 끄적였던거를 공유해보도록 하겠다.
pad후, reshape의 작동
여기 ddong라는 정사각 벡터가 있다고 가정하도록 하겠다.

쿼리와 임베딩벡터를 matmul해주면, (L, L)크기의 정사각 벡터가 나온다(L,d와 d,L의 matmul)
그 후, left padding을 해주고(나면 (L, L+1)의 크기를 가지게 된다)
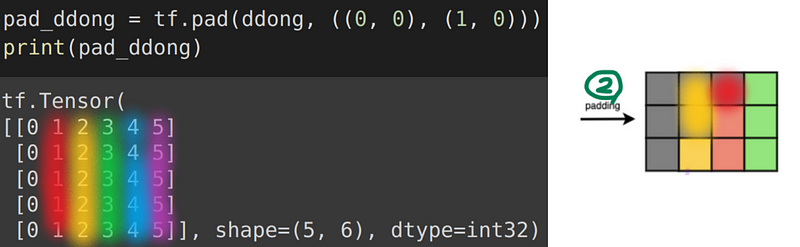
(L, L+1)의 벡터를, (L+1, L)로 reshape해주면 한칸씩 밀려들어가므로,
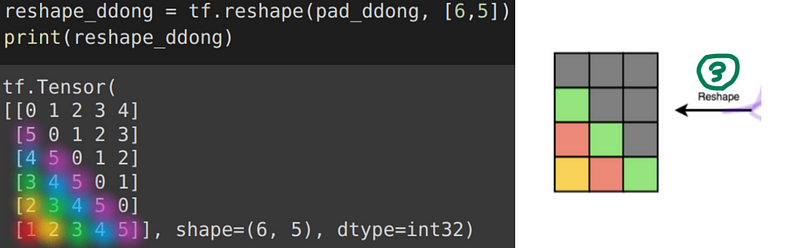
그 후 지붕을 떼어주면! S가 완성된다

(마스킹은 tf.linalg.band_part로 해주시면 된다)
.
.
마무리
이렇게 skewing을 통해 relative attention을 구하는 방법까지 알아보았다. 트랜스포머에 대한 지식이 있다면 relative attention 구현부분만 본다면, Music transformer를 손쉽게 구현할 수 있지 않을까 싶다. 하지만 음악 데이터를 다루어보지 않았다면, AI모델 자체보다는 음악데이터를 어떻게 전처리하는지에 대해 시간투자가 많이 들어가게 되지 않을까 싶다.
AI모델들을 다루어본 분들이 음악에서 손쉽게 AI모델들을 적용하는걸 도와주고자 글을 적었지만, 사실상 데이터에 대한 이해를 도와주는게 더 좋지 않을까 싶다. AI를 공부한 사람들이라면, 옆동네 모델들은 슥슥 금방 적용하지 않을까 싶다. 그런 의미에서 앞으로는 AI모델보다는, 그 앞단에서 선행되어야 할 음악 전처리(MIDI의 데이터 구조, 음악 데이터의 구조, BPM, velocity 등)에 대해 글을 적어보도록 하겠다.
마치며
언어모델들을 음악에 적용시 gpt2의 attention 부분만 relative attention으로 바꾸어 사용하기도 하며, 위와같이 트랜스포머의 어텐션만 바꾸어 사용하기도 한다. 그러므로 한번 작동 원리를 이해하고 나면, 추후 음악생성 AI모델을 만들 때, 이질감 없이 슥슥 적용 해 나갈 수 있지 않을까 싶다.
논문
트랜스포머: https://arxiv.org/pdf/1706.03762.pdf
뮤직트랜스포머: https://arxiv.org/pdf/1809.04281.pdf
shaw아저씨의 relative attention: https://arxiv.org/pdf/1803.02155.pdf
뮤직트랜스포머 이해에 도움을 주신 Rubato lab의 소준섭님: https://linktr.ee/SsojuBro
🌜 개인 공부 기록용 블로그입니다. 오류나 틀린 부분이 있을 경우
언제든지 댓글 혹은 메일로 지적해주시면 감사하겠습니다! 😄
댓글 남기기