
[AI X Music] 노래를 완벽한 MR로 만드는 법 (기술설명)
카테고리: medium
나만 아는 최애곡을 노래방MR로 만들 수 없을까?
나만 아는 최애곡을 노래방MR로 만들 수 없을까?
음원 분리 기술의 과거와 현재(1/2)
필자가 어렸을 때 읽었던 과학 용어 중 아직도 기억 나는게 있다. ‘칵테일 파티 효과’ 라는 용어이다. 시끄러운 환경에서도 누군가 내 이름을 부르면 기가 막히게 알아듣는 현상을 일컫는 용어이다. 초등학교 때,
“쓸데없는 소리로부터 유의미한 정보를 골라낸다는 점에서 ‘칵테일 파티 효과’는 몰컴 할때의 우리의 상태랑 비슷하지만, 몰컴 할 때에는 조용한 상태에서 유의미한 소리를 듣는 거니까 조금 다르지 않나요? 이럴 땐 뭐라고 해요?”
라고 선생님께 물었던 경험이 있다. 물론 대답은 들을 수 없었다. 이 때, 선생님이라는 위대한 존재에 대해 불신이 조금 더 쌓인 상태로 수업을 들었으며, ‘선생님도 사실 아는게 없는게 아닐까?’라는 불순한 생각으로 수업을 듣게 되는 계기 중 하나가 아니였나 싶다.
(혓바닥 맛 지도에 대해 의문을 제기했다가 혼났던 상태라 나도 분란을 일으키지 않고 그냥 넘어갔었다)
지금 와서 생각해보면, 두 가지 현상 모두 노이즈를 제거하고 원하는 신호만 뇌에서 집중적으로 연산이 이루어진다는 점에서, Source Separation 기술로 분류될 수 있지 않나 싶다. 아이폰에서 siri를 부를 때나, 음성 인식을 할 때도 비슷한 AI기술을 적용했을 것이라고 생각이 들었고, 한편으로는 전공 시간(디지털 회로설계)에서 Finite State machine을 이용한 특정 신호 검출 방법으로 유사하게 구현할 수 있지 않을까 싶었다.
전기전자를 전공하며, 신호처리와 ML쪽을 공부하다 보니 자연스럽게 연관 지식을 접할 수 있었고, 막연하던 추측에서 그 원리를 조금 더 깨우칠 수 있었다. 그 과정속에서 알게된, 음악에서의 그 적용을 한번 공유해보고자 한다.
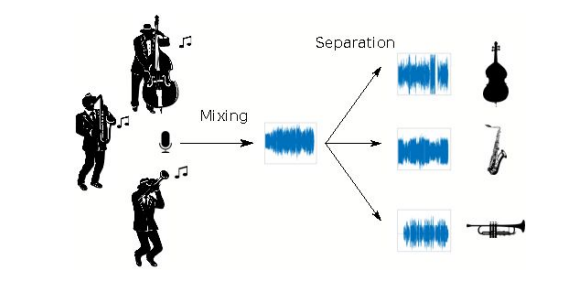
Source separation이라는 큰 주제에서, 음악(신호)에 대한 분야는 Music Source Separation이라고 불리워 진다. 음악에서 원하는 소스를 제외하면 어떻게 될까? 대표적으로는 보컬 제거가 있을 것이다.
음악에서 보컬을 빼면? = MR => 노래방 탄생!!
음원 분리 기술은 어떻게 발전해왔는지 그 과거, 현재, 산업에 대해 한번 글을 써볼까 한다. 라고 적었지만, 아무래도 음악 분리에 초점을 맞추어 작성해 볼까 한다.
I’ll write about (MSS)Music Source Separation. Let’s begin it.
목차
- 음악 분리 기술의 과거 <== (현재 글)
- 음악분리 기술(with AI)

Typical MSS workflow
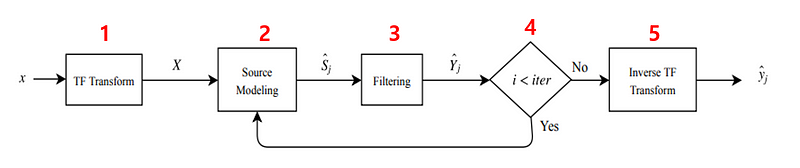
요즘은 물론 wavform에서 바로 분리해내는 연구들도 진행되고 있지만, 통상 위처럼 주파수 도메인에서 분리해낸다.
1.TF transformation
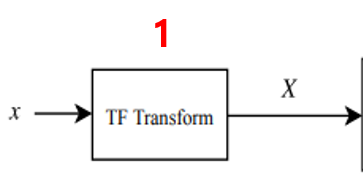
음성 신호가 들어오면 STFT변환을 통해 Spectrogram으로 변환해준다. Constant Q transform도 사용 가능하지만… 아직 많이 쓰이고 있지는 않다.
2. Source modeling

스펙트로그램을 분석해서 소스를 모델링 한다. 음악 신호의 특성(source의 특징, mixing과 recording의 특징 등)을 이용한다.
3. Filtering
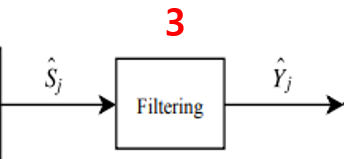
즉 모델링 된 소스를 마스킹을 통해 분리하는 것이다.(분리된 music source를 estimation하는 것이 필터링의 주 목적이다. GWF와 같은 soft-making을 이용한다.)
4. Iteration!!
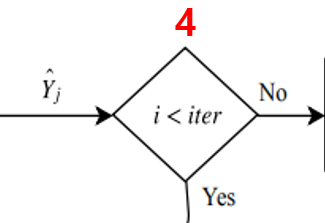
Expectation-Maximization알고리즘으로 평가 & 필터링을 반복한다.
5. Inverse transform
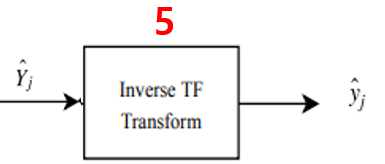
다 되었다~라고 (컴퓨터가)생각되면, frequency domain => time domain 변환!
.
.
MSS models
위의 MSS(Music Source Separation) workflow를 보면, (뻔한)STFT전처리를 수행해주고, 다시 역변환하는게 끝이다. 결국 핵심은 MSS모델이다. 한 번 어떤 MSS 모델들이 있는지 알아보도록 하겠다.
Musical Source positional model
글의 서두에서 언급한 칵테일파티 효과를 다시 한 번 떠올려보자. 우리가 생활을 하면서 인지할 수 있는 중요한 정보중 하나는… 바로바로… 소리의 위치이다. 집 밖의 큰 소리는 무시할 수 있어도, 귀 옆의 작은 소음은 무시하기 힘들다.
따라서 예전부터 ICA(Independent Component Analysis)방식을 이용 해 음원분리를 시도해왔었다. ICA에 대해 검색을 하면
다변량의 신호를 통계적으로 독립적인 하부 성분으로 분리하는 계산 방법
이라고 나온다.
보기만 해도 머리가 어질어질 해 지는 용어로 설명을 해 놓아서 처음엔 화가 났지만, 영어로 작성된 블로그를 몇 개 보다 보니 조금 더 직관적으로 알 수 있게 되었다. 내가 해석해낸 ICA는 “이쯤 있겠지? 계산방법” 이다.

BSS(Blind Source Separation)의 일종인 ICA는, 독립적인 랜덤 변수들의 선형조합으로 이루어진 조합은 가우스분포를 따른다는, CLT(Central Limit Theorem)을 역으로 연산시킨 것이다.
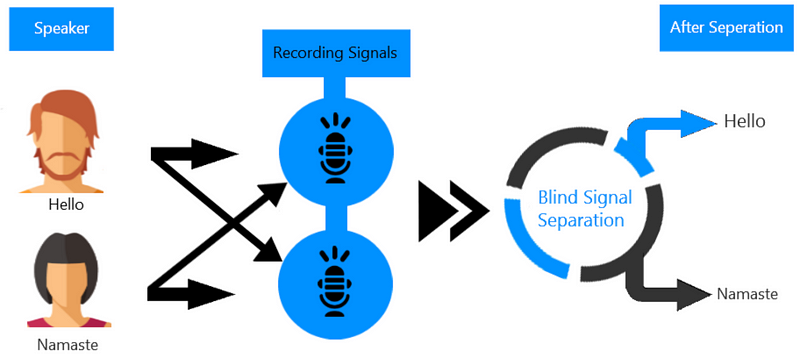
결국 분리하고 나오면 이렇게 나오겠지? 라고 추정되는 정보값이 있기에 역으로 연산해서 소스를 분리해낼 수 있다는 말이다. 따라서 Linear하지 않은 상황, ex)reverb, delay등이 있는 상황이라면 전통적인 ICA방식은 잘 작동하지 않는다. 결국, 딥러닝에서 자주 사용되는 PCA기법처럼, 중심이 되는 기저벡터를 찾아줄 수 있고, 이를 통해 음원을 분리 해 내는 것이다.
그렇다면 음악에서의 MSS방식은 어떨까? 오늘의 하이라이트 내용을 좀 더 알아보도록 하겠다.
정~말 감사하게도, 수많은 믹싱 고수들이 음원의 위치를 어느 정도 잡아주셨다. 눈을 감고 노래를 들을 때, 가수의 목소리가 왼쪽에 있거나 오른쪽에 있다고 생각된 적이 있을까?
일부러 패닝을 넣은 경우가 아니라면 vocal의 목소리 상은 정 가운데에 맺힌다. 오케스트라 공연을 보러가면 피아노의 위치, 관악기와 현악기의 위치는 정석적인 위치를 따라간다. 악기와 목소리의 특성에 따라서 적정 위치가 있기 때문에 음악에서의 음원 분리는 그나마 조금 더 쉬운(?이라고 말하기에는 여전히 어려운..) 기술이라고 볼 수 있다.
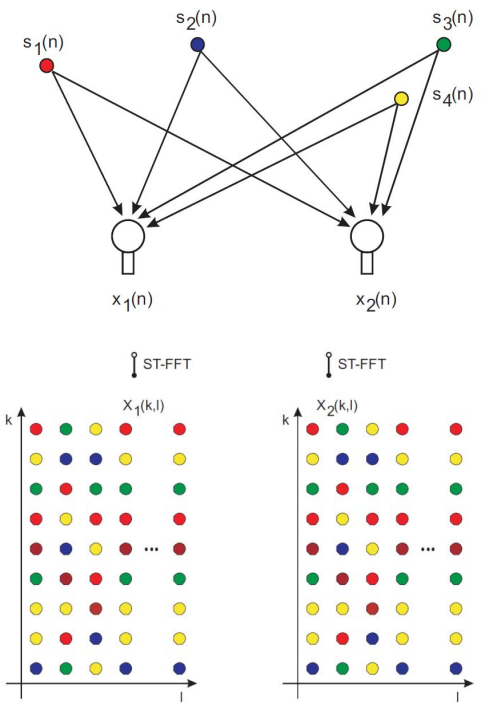
하지만 위의 ICA방식으로 소스를 분리하려면 분리하려는 소스의 개수만큼 채널이 있어야 한다. 이는 stereo로 여러가지 악기를 분리할 수 없다는 뜻이다. 이와 같은 점은 통상적으로 사용되는 2채널 신호를 원하는 대로 분리해 내는데 큰 단점으로 작용한다.
따라서 소스가 채널보다 많을 때를 위해, 아래와 같은 모델들이 연구되었다.
- DUET(Degenerate Unmixing Estimation Technique)
- ADRess(Azimuth Discrimination Resynthesis)
- PROJET(PROJection Estimation Technique)
중간정리
- BSS의 일종인 ICA방식은 중심극한 정리를 역으로 취함으로써, 변환 행렬을 유추할 수 있고, 이를 통해 소스 분리를 할 수 있다.
- 감사하게도 음악 소스분리 (MSS)에서는 각 악기에 해당하는 추정치가 있고, 이를 활용해 조금 더 쉽게 분리를 해낼 수 있다.
- ICA방식을 적용하기 위해서는 소스의 수만큼 채널이 있어야 하므로, 이와 같은 단점을 극복하기 위해 다양한 모델들이 개발되고 있다.
그렇다면 위에서 언급한 DUET, ADRess, PROJET와 같은 MSS모델들의 추정 방법을 알아보도록 하겠다.
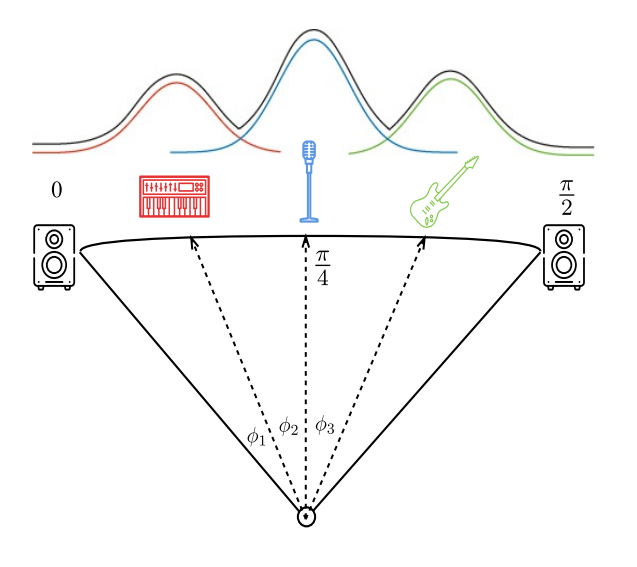
각 음원의 소스에는 Sound Engineering적 요소(delay나 panning 등)가 어떻게 작용하는지에 대해 모델링이 되어 있다. 이를 수학적으로 적절히 알고 있기에, 소스보다 채널이 더 적을 때 적절히 소스를 유추할 수 있다. DUET과 ADRess는 소스들의 spatial position과 binary masking을 이용해서 음원들의 Peak위치를 찾아내고. 어떤 소스들이 각각의 채널로 (자~알 나누어서)들어왔는지 알 수 있다.
결국 입력된 신호들의 에너지를 이용하거나, 각도를 이용하거나 이다. PROJECT는 angle을 이용한다.
GWF필터를 활용하여 histogram에 masking하고, position histogram과 mixture spatial histogram을 사용해서 음원의 위치를 파악할 수 있다. 위의 그림에서 히스토그램상 피크지점을 각각의 소스로 할당한다. 소스의 position의 위치를 추정해 분리하는 방식이므로 위의 히스토그램에서 소스가 겹쳐있는 부분은… 분리해 낼 수 없다. 지금 설명한 모델들이 어떤 역할인지 다시 헷갈릴 수 있는데, 지금 말하고 있는 3가지 모델들은 모두 MSS모델중 source position model들이다. 위의 모델들 모두 음원의 위치정보로 분리하기 때문에 기타, 키보드, 보컬이 모두 중앙에 위치되어 있다면 음원을 분리해 낼 수 없다. 그렇다면 (source별 position이 존재하지 않는)모노 사운드나, 음상이 가운데에 모여있는 스테레오 사운드의 경우에는 어떻게 분리해 낼 수 있을까?
.
Music source models
이 경우에는 Music source model들을 사용한다. 타겟 소스의 spectral특징을 통해 분리해 내는 방식이다. 추후 이야기 하게 될 딥러닝 쪽에서의 분리들은 대부분 이 방식이다. 당연한 이야기지만 음악을 들을 때, 악기와 보컬을 우리가 개별적으로 인지하는 이유는 음원의 위치도 중요하겠지만, 악기의 소리특징과 보컬의 특징이 개별 소리로 인지하는 가장 중요한 이유이다. (=트럼펫 소리와 꽹과리 소리를 구분 못하는 사람이 있을까?)
Music source model에는 다음과 같은 방식들이 있다.
1. Kernel models
2. Spectrogram factorization models
3. Sinusoidal models
4. Deep neural network models
하나하나 살펴보도록 하겠다.
1) Kernel models
kernel additive model같은 음원 분리 모델은 spectrogram에서 반복되고 연속되는 local feature들을 활용한다.

KAM에는 다양한 형태의 커널이 있다. Harmonic한 소리와 percussive 소리는 그 형태가 다르듯, 커널의 형태도 다르다. 내가 찾고싶은 target source 이외에는 간섭이 sparse하다고 가정하고, 간섭이 있는곳의 TF bin들은 outlier로 간주하여 소스를 분리한다.
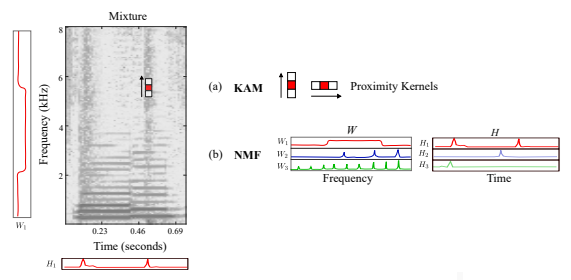
proximity kernel을 설정하고, 위의 방식으로 iteration을 돌며 outlier를 뽑아내는 것이다. 드럼과 같은 경우, 짧은 순간 ADSR을 거치며 다양한 frequency를 가진다. 따라서 아래와 같이 수직적인 특징이 생긴다

하지만 harmonic sound와 같은 경우 일정한 간격(의 주파수 성분)으로 배음을 가지며, 아래와 같이 수평적인 특징을 가져간다.
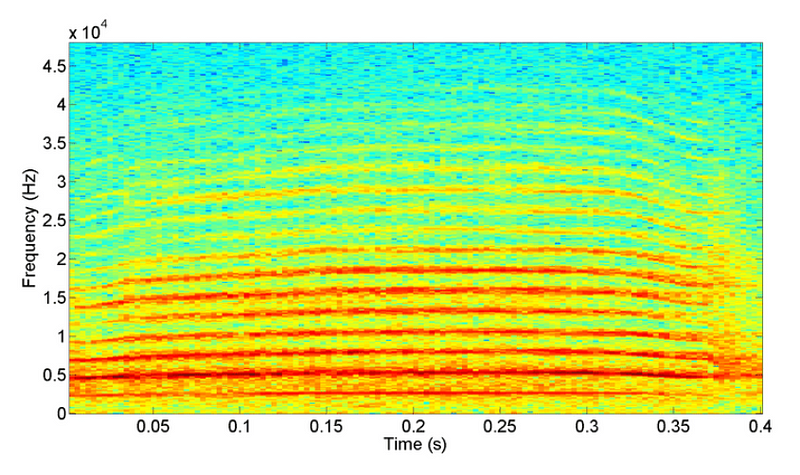
따라서 설정한 Proximity kernel을 좌우 위아래로 iteration을 돌게하며 음의 특징을 찾아내고, 분리할 수 있는 것이다.
2) Spectrogram factorization models
두번째로는 nonnegative matrix factorization(NMF)으로도 불리우는 spectrogram factorization model이다. 우리가 분리하고 싶은 소리와, 다른 소리들(노이즈로 생각할 수 있는 것들)을 포함하고 있는 행렬 V가 있다고 생각해 보자. V = WH로 나눌 수 있을테고, 우리는 W(주파수영역)와 H(시간영역)행렬이 V를 잘 표현해주길 바라며 분리를 하는 것이다.
행렬을 쪼갠다는 점에서, PCA와 SVD도 적용 가능하지 않나? 라고 생각 해 볼 수 있다. 하지만 두 알고리즘 모두 직교 하는 두 행렬로 쪼개진다. 직교하는 두 행렬은 아래 그림과 같이 전체 데이터를 잘 표현하지 못할 수 있다.
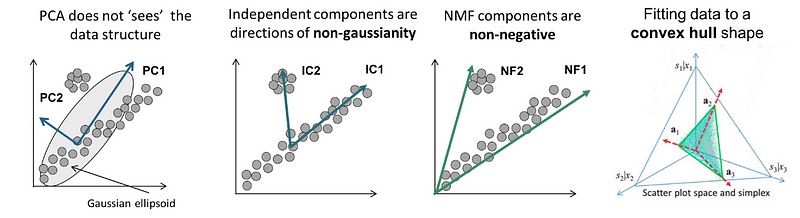
우리의 spectrogram은 모두 양수의 값을 가지고 있고, 이러한 경우 NMF기법을 적용해 볼 수 있다.
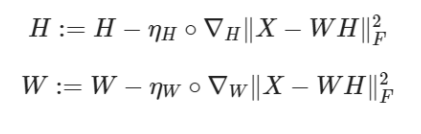
W는 소스별 feature에 대한 weight라고 생각하고, H는 소스별 feature이라고 생각하면 될 것 같다. 따라서 V가 WH로 잘 나누어지게 된다면, 어떤 특징들을(W) 얼마만큼(H) 쓸건지 알 수 있다.
딥러닝처럼 학습을 열심히 시키지만, 네트워크가 워낙 간단하니.. 쩝 생각보다 vocal을 추출하는데에 있어 성능이 잘 안나온다고 한다. 악기의 경우는 사람 목소리보다 일정한 부분이 있으므로 괜찮게 된다고 한다.
3) Sinusoidal models
모든 음악 신호는 결국 sinusoidal한 신호의 조합으로 (거의)표현 할 수 있다는 가정에서 출발 된 알고리즘이다. 대부분의 경우 fundamental frequencies(F0)와 harmonic series의 set으로 구성된다.
하지만 악기의 특성을 이미 자세하게 알고 있어야 한다. 해당 악기의 음별 Timbre까지도 세세하게 알고 있어야 분리를 할 수 있으며, 이런 제한된 기술 요건 때문에 잘 사용되지 않는다.
4) Deep neural network models
말이 필요한가. 딥러닝으로 음원을 분리하는 방법이다. 가장 연구가 많이 되는 방법이고, 역사도 있으므로
다음 글에서 자세히 다루어 보도록 하겠다.
사용했던 용어들로 내용 정리
이번 글에서 MSS에 대해 알아보았다. 음원분리는 결국 주파수영역으로 전처리를 하고, 모델을 통과시키고, 다시 후처리를 해서 분리된 음원으로 원복시킨다. 결국-결국-결국 논의할 부분은 중간의 MSS(음원 소스 분리) model이며, MSS model은 크게 두 가지로 나누어 볼 수 있다. 음원의 위치로 분리하는 방법과 음원 소리의 특징을 통해 분리해내는 방법이 있다.
음원 위치로 분리해내는 방법, BSS의 대표적인 방법으로는 ICA가 있으며, 이는 분리하고자 하는 소스의 개수만큼 채널이 있어야 한다. 그래서 이를 보안하기 위해, DUET, ADRess, PROJET 와 같은 방법을 쓴다.
음원 소리의 특징을 통해 분리해 내는 방법에는 KAM, NMF, Sinusoidal 그리고 딥러닝을 통한 분리가 있다.(딥러닝은 다음 글에서..)
그리고 이렇게 분리된 모델을 테스트 할 때에는, 딱히 통합된 방법이 없기 때문에 BSS_eval을 통해 얼마나 음원 분리가 잘 되었는지 평가한다고 한다.
MSS와 Source Separation에 대한 단상
음악 업계에서 가장 유명한 MSS툴은 izotope사의 ‘그것’일 것이다. 뮤직 프로덕션 용으로 쓰시는 분들은 MSS보다는 샘플링 툴, 개념으로 익히 알려져 있을 것이다. izotope사의 RX9을 써보았다. 내가 만들고자 하는 음원에 다른 음악의 보컬을 샘플링 하고자 할 때 썼었다.
좋았는가? 물론 아니였다. 생각만큼 깔끔하게 분리되지 않았다. 당시 업계 최고라고 했지만, 직접 써보면 불필요한 드럼 비트가 섞여 들어와서 사용할 수 없었다.
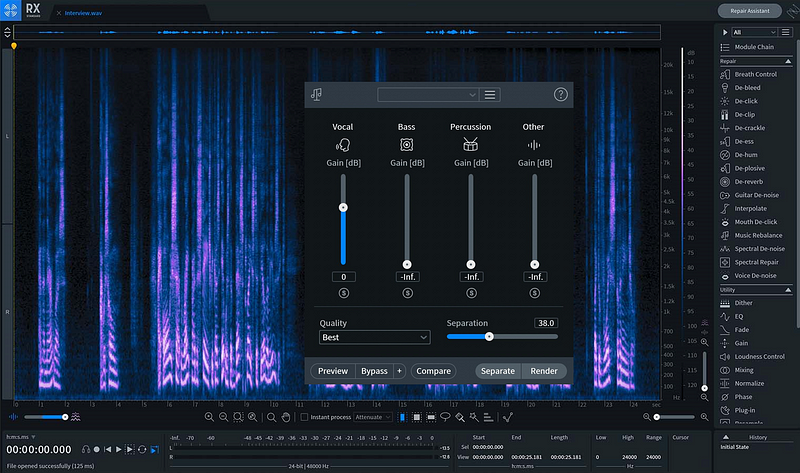
ISMIR과 같은 학회에도 최근(2021)에도 Source Separation으로 투고를 하는 등 지속적인 연구가 이루어지고 있다. (but… 상용으로 쓰기에는 조금 아쉽)
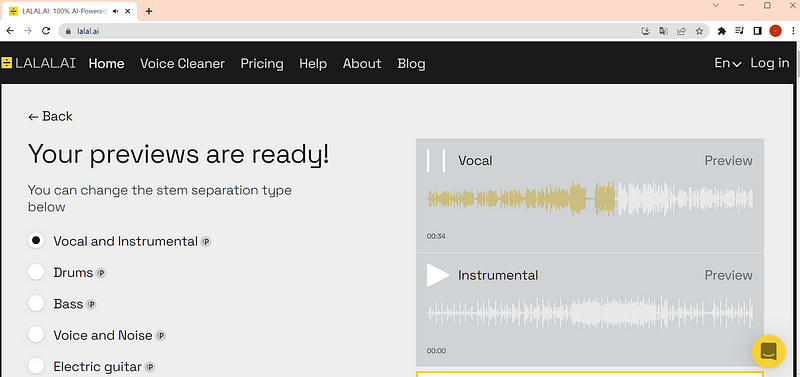

AI를 통한 Separation툴들이 시장에 점점 늘어나고 있다. 누가 더 완벽한 음원분리를 하는지에 대한 경쟁 구도이기도 하지만, 결국은 두 가지 요건이 시장에서의 경쟁력을 확보하지 않을까 싶다.
1. 어떤 서비스가 목적인지
2. 어떤 데이터를 가지고 있는지
서비스의 목적에 대한 부분은 기업의 실 수익을, 데이터 확보는 서비스의 지속성(기술력)을 확보할 수 있는 원천이 될 것이다.
Spotify의 라이벌이라고 불리우는(과연?후훗..) Deezer은 Source separation으로 가라오케 서비스를 제공하고자 했었다.
I was wondering if anyone could help create a simple python program to create karaoke tracks using this. Here's what I…github.com
음원 분리로 노래방을 만든다? 누구나 할 수 있는 발상이지만 실제 시장에 나와있는 제품이 없음을 고려했을 때, 수요가 부족하지 않나 싶다. 음주가무의 민족인 한국에서는 또 다를 수도 있겠지만…
AI assistant에 정확한 목소리 전달을 위한 잡음 제거, 무선 이어폰으로 통화를 위한 잡음 제거, 음원 에서의 잡음(보컬을 제외한) 제거, 화상회의를 위한 키보드 잡음 제거 등 사람의 정확한 목소리를 얻고자 하는 수요는 넘쳐난다. 하지만 아직.. 어려운 것 같다.
화상회의를 할 때는 딜레이가 있으면 안되지만, 샘플링으로 음악을 만들고자 할 때는 성능만 좋다면 어떤 기다림도 감내할 것이다. Alexa에게 부탁을 할 때는 내부 GPU에서 처리하겠지만, 통화를 할 때는 모바일 환경에서 처리를 해야 할 것이다. 목적에 딱 맞는 MSS model들이 개발되어야 하고, 좀 더 경쟁력을 갖추기 위해 실 사용 환경에 맞는 데이터도 존재해야 한다.
하지만 특정 목적에 맞는 데이터는 기업에 종속되어 있을 것이고, 그 데이터를 이용해 딥러닝 모델이든, 수학적 모델링이든, 유저 사용 패턴이든 다양한 방식으로 분석되고, 비즈니스 경쟁력을 끌어올리지 않을까 싶다. (이미 최근 6년 간 다들 그렇게 해 왔지 않을까)
결국 방구석에서 기가 막힌 발명을 해서 성공하는 시대는 끝났다고 생각한다.기가 막힌 MSS방법을 알게 되었다고 한들, 떵떵 거릴만한 부자가 되거나 길이 남을 과학자로 인정받기는 힘들 것이다. 그리고 그 과정 속에서 사실 많은 사람의 도움을 받았으리라 생각된다.
(여기서 성공은 부자가 된 상태를 말한다)
무튼, 뛰어난 능력으로 뛰어난 발견을 한들, 사람들을 많이 만나며 새로운 비즈니스(목적)를 찾아내거나, 많은 사람들과 협업 해 나가면서 데이터(기술)를 쌓아나가며 고도화를 해야 성공할 수 있지 않을까 싶다.
🌜 개인 공부 기록용 블로그입니다. 오류나 틀린 부분이 있을 경우
언제든지 댓글 혹은 메일로 지적해주시면 감사하겠습니다! 😄
댓글 남기기